具体分析请求和返回参数,完全描述准确,DeepSeek 就能帮你生成准确的代码。
当然描述不是一下就可以描述准确,会经过多次修改,只到完全符合要求,DeepSeek 代码实现能力毋庸置疑。
DeepSeek提问需求:
写一个功能,get调用 headers中添加cookie参数,值为uid=xxxxx; token=d4xxxxxx414d7a,page参数从1循环执行到每次加1, 返回结果中data下有个data参数,对应的值是数组的,在每次返回结果中统计出model值, model为空或null时跳过,chi为1时不统计,type为1时不统计,若包含“ipad”或“iPad”的个数, 判断数组中结果tjtime值小于1733673600停止查询。
代码:
import requests
import time
from datetime import datetime
def count_special_ipad():
# 请求配置
headers = {
"Cookie": "uid=38; token=d4df3b9c-d306-4a9b-9a09-a46670414d7a",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
# 时间阈值(2024-12-09 00:00:00 UTC)
stop_timestamp = int(datetime(2024, 12, 9).timestamp())
base_url = "https://xxxx.xxxx.cn/index/index/DevicelistPage"
page = 1
total_count = 0
stop_flag = False
while not stop_flag:
print(f"\n▶ 正在处理第 {page} 页 [累计:{total_count}]")
page_count = 0
try:
# 发送带重试机制的请求
response = requests.get(
base_url,
headers=headers,
params={"page": page, "zt": "all"},
timeout=10
)
response.raise_for_status()
# 解析嵌套数据结构
json_data = response.json()
device_list = json_data.get('data', {}).get('data', [])
if not isinstance(device_list, list):
print("⚠ 数据格式异常: data.data 不是数组")
break
# 遍历设备处理
for device in device_list:
# 停止条件检查(tjtime时间戳判断)
tjtime = device.get('tjtime')
if tjtime:
try:
if int(tjtime) < stop_timestamp:
print(f"🛑 触发停止条件: {datetime.fromtimestamp(int(tjtime))}")
stop_flag = True
break
except (ValueError, TypeError):
pass
# 过滤条件1:chi=1
if str(device.get('chi', '')).strip() in ['1', 1]:
continue
# 过滤条件2:type=1
if str(device.get('type', '')).strip() in ['1', 1]:
continue
# 过滤条件3:model有效性检查
model = str(device.get('model', '')).strip()
udid = str(device.get('udid', '')).strip()
if not model or model.lower() == 'null':
continue
# 核心匹配逻辑(不区分大小写)
if 'ipad' in model.lower():
page_count += 1
print(f"✅ 发现: {model[:100]} - {udid[:18]}... ")
total_count += page_count
print(f"第 {page} 页结果: +{page_count} 台")
# 翻页控制
page += 1
time.sleep(1)
except requests.HTTPError as e:
print(f"HTTP错误({e.response.status_code}): {e}")
break
except requests.RequestException as e:
print(f"网络异常: {str(e)}")
break
except Exception as e:
print(f"系统错误: {str(e)}")
break
print("\n" + "="*40)
print(f"扫描终止页数: {page-1}")
print(f"最终统计结果: {total_count} 台iPad设备(符合条件)")
print(f"停止时间阈值: {datetime.fromtimestamp(stop_timestamp).strftime('%Y-%m-%d %H:%M:%S')}")
if __name__ == "__main__":
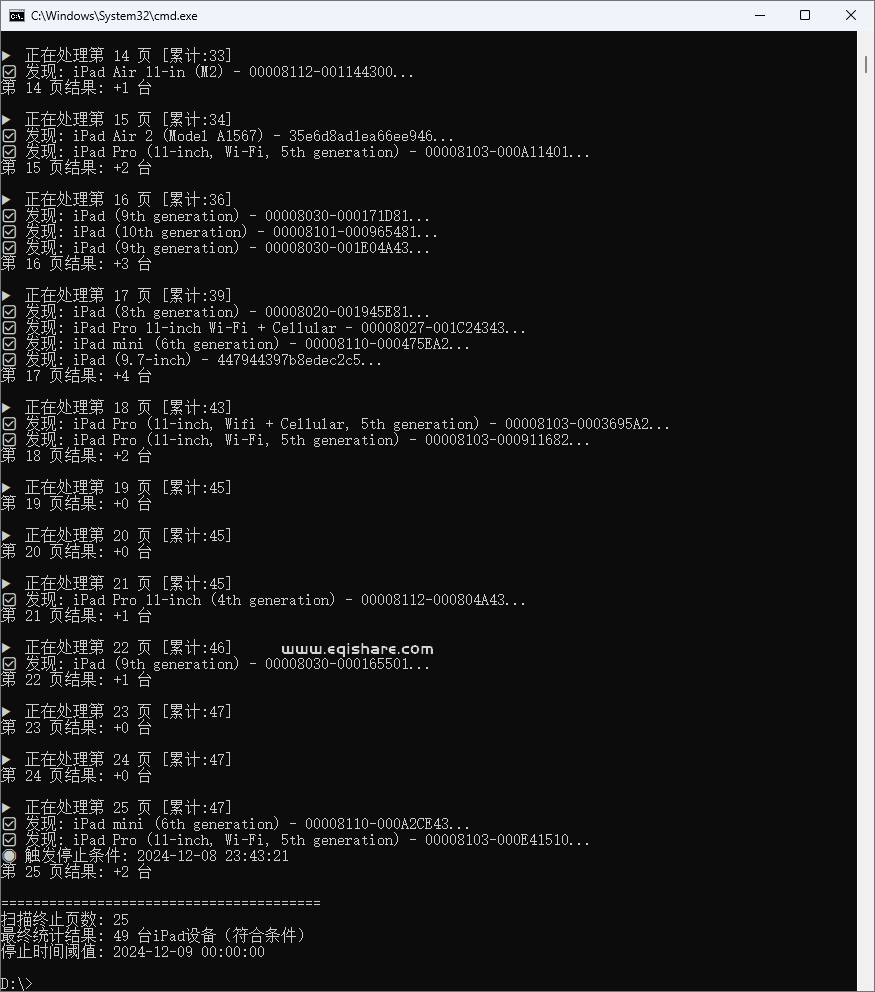
count_special_ipad()执行结果:
PS:有这方面需要的老铁,可以找联系我。







